My Projects
PythonLangchainOllamaLama3.2FAISS
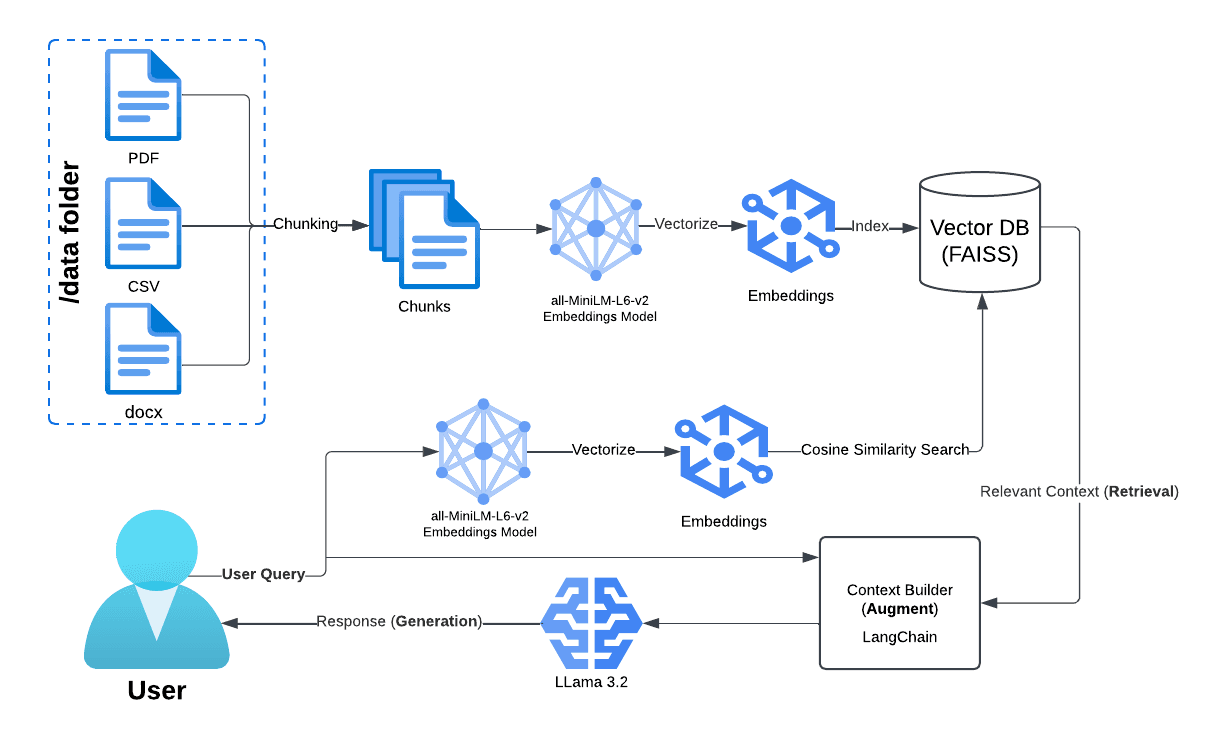
A local implementation of a Retrieval-Augmented Generation (RAG) pipeline using a local Llama 3.2 via Ollama. This project allows document-based question answering by integrating document loading, vector database storage, and a conversational retrieval system.
This project was derived from a Caselaw RAG project I worked on using Harvard's Caselaw Access Project which used the OpenAI API and Pinecone. This project is an extension of it's capabilities, but takes into consideration privacy concerns by doing the augmentation locally instead of with a vector store in the cloud.